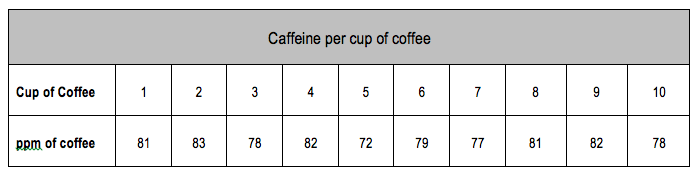
In statistical analysis, identifying outliers is crucial for ensuring the integrity of data interpretation. Two effective methods for detecting outliers in datasets are Grubbs' test and the Q test, each serving specific scenarios based on the dataset's characteristics.
Grubbs' test is designed to identify a single outlier in a normally distributed dataset. To apply Grubbs' test, the first step is to calculate the Grubbs' statistic, denoted as \( g_{\text{calculated}} \). This is done using the formula:
\( g_{\text{calculated}} = \frac{|\text{suspected outlier} - \text{mean}|}{\text{standard deviation}} \)
Once \( g_{\text{calculated}} \) is determined, it is compared to a critical value from the Grubbs' table, which varies based on the number of observations and the desired confidence level (90%, 95%, or 99%). If the critical value from the table is less than \( g_{\text{calculated}} \), the suspected outlier is discarded, necessitating a recalculation of the mean and standard deviation for the remaining data. Conversely, if the critical value is greater than \( g_{\text{calculated}} \), the outlier is retained as it falls within acceptable limits of variation.
The Q test, while less commonly discussed, is particularly useful for small datasets, typically containing between 3 to 7 measurements. The Q statistic is calculated using the formula:
\( q_{\text{calculated}} = \frac{\text{gap}}{\text{range}} \)
In this context, the gap is defined as the absolute difference between the suspected outlier (\( x_1 \)) and the next closest data point (\( x_{n+1} \)), expressed as:
\( \text{gap} = |x_1 - x_{n+1}| \)
The range is determined by subtracting the smallest value from the largest value in the dataset:
\( \text{range} = \text{largest value} - \text{smallest value} \)
To utilize the Q test, the dataset must be organized in ascending order. Similar to Grubbs' test, the calculated Q value is compared to a critical value from the Q table. If the critical value is lower than \( q_{\text{calculated}} \), the suspected outlier is rejected. If it is greater, the outlier is accepted as part of the dataset.
In summary, both Grubbs' test and the Q test are valuable tools for identifying outliers, with Grubbs' test being more widely used for larger datasets, while the Q test is reserved for smaller datasets. Understanding and applying these tests can significantly enhance data analysis accuracy.