So in example 2 it states, can either or both of these suspects be eliminated based on the results of the analysis at the 99% confidence interval? Now realize here because in example 1 we found out there was no significant difference in their standard deviations, that means we're dealing with equal variance. Because we are dealing with equal variance, this dictates which version of s_{\text{pooled}} and t_{\text{calculated}} formulas we'll have to use. Now since there's going to be a lot of numbers on the screen, I'll have to take myself out of the image for a few minutes. So let's look at suspect 1 and then we'll look at suspect 2 and we'll see if either one can be eliminated.
For suspect one, we're dealing with equal variance in both cases, so therefore s_{\text{pooled}} = \sqrt{s_1^2 \times (n_1 - 1) + s_2^2 \times (n_2 - 1)} / (n_1 + n_2 - 2) . Alright. So for suspect 1, we're comparing the information on suspect 1 to the sample itself. We'll be using the values from these two for suspect 1.
Let’s come back down here. And before we come back actually, we're going to say here because the sample itself. Alright. We can say here that, we'll make this one s_1 and we can make this one s_2 , but it really doesn't matter in the grand scheme of our calculations. So we come back down here, we'll plug in s_1 = 0.073^2 \times (4-1) + 0.088^2 \times (6-1) / (4+6-2) .
When we plug all that in that gives us \sqrt{0.006838} , and that comes out to 0.082694 for s_{\text{pooled}} . Now that we have s_{\text{pooled}} we can figure out what t_{\text{calculated}} would be. So t_{\text{calculated}} , because we have equal variance, equals in absolute terms \frac{|x_1 - x_2|}{s_{\text{pooled}} \sqrt{\frac{n_1 \times n_2}{n_1 + n_2}}} . So the mean or average for the suspect one is 2.31 and for the sample 2.45. We've just found out what s_{\text{pooled}} was, so plug that in Times the number of measurements, so that's 4 \times 6 / (4+6) .
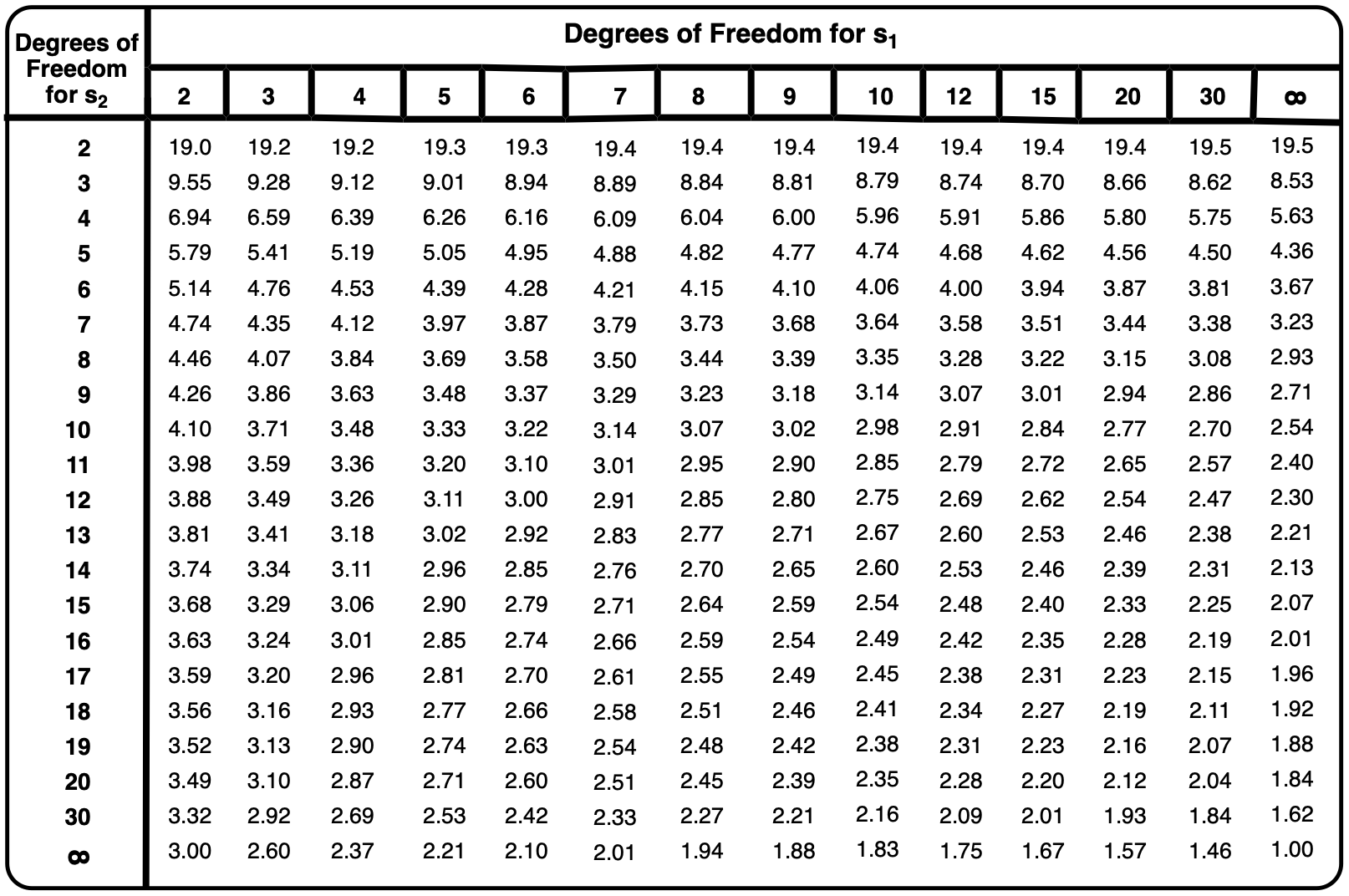
So all of that gives us 2.62277 for our t_{\text{calculated}} . Now, if t_{\text{calculated}} is larger than t_{\text{table}} , then there would be a significant difference between the suspect and the sample. Here, if you use a t table, our degrees of freedom are normally n - 1 , but in comparing the two to one another, my degrees of freedom now become this, n_1 + n_2 - 2 . So that would be 4 + 6 - 2, which gives me a degree of freedom of 8. If you go to your t table, look at 8 for the degrees of freedom, and then go all the way to the 99% confidence interval.
That gives us a t_{\text{table}} value equal to 3.355. So what is this telling us? Well, this is telling us that our t_{\text{calculated}} is not greater than our t_{\text{table}} . t_{\text{table}} is larger, so that means there is no significant difference between suspect 1 and the sample.
So that means suspect 1 could be guilty of the oil spill because t_{\text{calculated}} is less than t_{\text{table}} . There's no significant difference. Suspect 1 is a potential violator. Now let's look at suspect 2. So suspect 2 we're going to do the same thing.
s_{\text{pooled}} equals the same exact formula, but now we're using different values. We're comparing suspect 2 now to the sample itself. So suspect 2 has a standard deviation of 0.092, which we'll square times its number of measurements which is 5 minus 1, plus the standard deviation of the sample, and that's also squared. It had 6, 6 samples minus 1, divided by 5 + 6 minus 2. So here that gives us \sqrt{0.008064} .
So that equals 0.0898. Now that we have s_{\text{pooled}} we can find t_{\text{calculated}} here, which would be the same exact formula we used here. So here the mean of my suspect 2 is 2.67 minus 2.45 divided by my s_{\text{pooled}} , which we just found, times 5 times 6 divided by 5 + 6. So that's 2.44989 times 1.65145.
So t_{\text{calculated}} here equals 4.04586. My degrees of freedom would be 5 + 6 - 2, which is 9. So we look up 9 for our degrees of freedom, we go all the way to the 99% confidence interval, so t_{\text{table}} equals 3.250. So in this example t_{\text{calculated}} is greater than t_{\text{table}} . That means there is a significant difference between the sample and suspect 2, which means that they are innocent.
So in this example, which is like an everyday analytical situation, where you have to test crime scenes and in this case an oil spill to see who is truly responsible, we can see that suspect 1, there was no significant difference because t_{\text{calculated}} was not greater than t_{\text{table}} . So suspect 1 is responsible for the oil spill. Suspect 2, if t_{\text{calculated}} was greater than t_{\text{table}} , so there is a significant difference, therefore exonerating suspect 2. So again, if we had had unequal variance, we'd have to use a different combination of equations for s_{\text{pooled}} and t_{\text{calculated}} , and then compare t_{\text{calculated}} again to t_{\text{table}} . So, again, the F-test really is just looking to see if our variances are equal or not, and from there it can help us determine which set of equations to use in order to compare t_{\text{calculated}} to t_{\text{table}} .